Cloud-based computing infrastructure for large scale neural data analysis
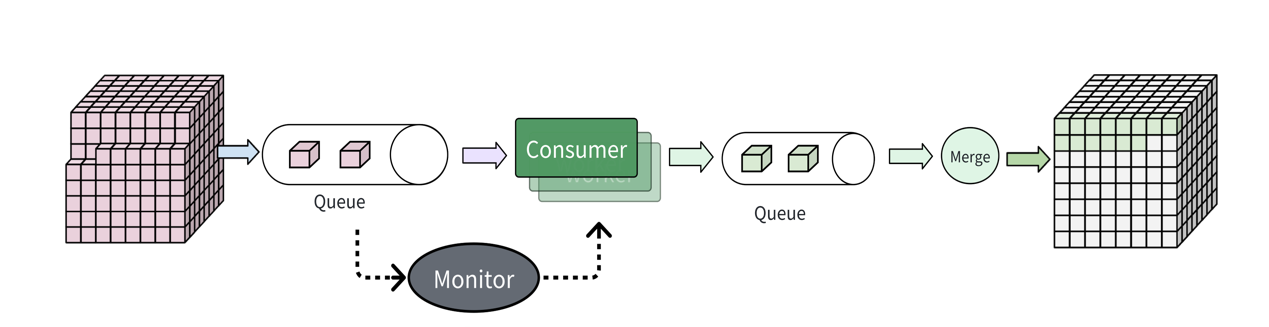
The massive scale of modern neuroscience data poses significant challenges in storage, sharing, processing, and analysis, requiring specialized expertise often unavailable to individual labs. While open-source tools exist, integrating them into complete pipelines remains challenging. To address this, we're developing Kubernetes/Docker-based cloud servers that organize data analysis into three specialized roles—domain scientists (research questions), data scientists (computational tasks), and engineers (infrastructure)—connected through well-defined interfaces to minimize dependencies and streamline workflows. This infrastructure currently supports our internal pipelines, with plans to generalize it for broader neural data analysis applications.